图算法学习笔记
2023-08-23
1 图算法
1.1 基本定义
定义:图的结构是由顶点和边构成。 规范定义为 图是由顶点的有穷非空集合和顶点之间的边的集合组成,通常表示为: G =( V , E ) V是顶点集合,E是边的集合。霁轩
图 \(G=(V, E)\) : - 节点集 \(V\); 节点数量 \(n=|V|\);
边集 \(E\); 边数量 \(m=|E|\);
邻居矩阵 \(A\);
度矩阵 \(D\);
归一化邻接矩阵: \(P=D^{-1 / 2} A D^{-1 / 2}\)
归一化拉普拉斯䞠阵: \(L=I-D^{-1 / 2} A D^{-1 / 2}\)
节点特征矩阵 \(X \in \mathcal{R}^{n \times f}, f\) 代表特征维度。
(注意:线性表中无元素,则为空表,树中无节点,则为空树,但在图中,顶点数不能为0,边数可以为0。)
1.2 有向边和无向边、有向图与无向图
两个顶点之间的边的有无方向,判定它为有向无向,
任意两个顶点的边是有向边的图为有向图,同理,为无向图。
1.3 简单图
简单图就是图中没有环,没有重边(两个顶点存在两条及以上的的边)。 数据结构中讨论的是简单图。
1.4 邻接、依附
若两个顶点之间有边,则称为这两个点邻接。这个边也依附于这两个点。 (线性表中数据元素仅有线性关系,树中节点有层次关系,图中任意两个点都有可能有关系。)
1.5 完全图
任意两个顶点之间都存在边。(有向完全图则为任意两个顶点之间存在互相指向的边。) 含n个顶点的完全图有 1/2 ×n(n-1)条边,有向完全图则为它的2倍。
1.6 稀疏图与稠密图
根据边的多少判断。
1.7 顶点的度
度有入度和出度,该顶点的度就是依附于该点的边数。入度和出度是有向图里的,指向该点的边数为入度,从该点出发引出的边数则为出度。
1.8 权图与网图
权是给边赋予有意义的值, 带权的图称为网图。
1.9 路径、路径长度
从一个顶点到另一个顶点经过的顶点序列,v1v2v3…vi; 路径长度=路径经过的边数(无权),在网图中则为经过边数权值之和。
1.10 连通图、连通分量
图中任意两个顶点都存在路径,都可达,则称该图为连通图。 非连通图的极大连通子图为连通分量。
1.11 生成树、生成森林
由图中所有的顶点构成的无回路的连通图。 每个连通分量都可生成树,组成森林。
1.12 同构图、异构图
同构图:百度文库 同构图: 在图里面, 节点的类型和边的类型只有一种的图, 举个例子, 像社交网络中只存在一种节点类型, 用户节点和一种边的类型, 用户-用户之间的连边。
异构图: 与同构图相反, 异构图是指图中的节点类型或关系类型多于一种。在现实场景中, 我们通常研究的图数据对象是多类型的, 对象之间的交互 关系也是多样化的。因此, 异构图能够更好地贴近现实。 异构图: 在图里面, 节点的类型+边的类型 \(>2\) 的一种图, 举个例子, 论文引用网络中, 存在着作者节点和paper节点, 边的关系有作者-作者之间的共同创作关系连边, 作者-论文之间的从属关系,论文-论文之间的引用关系。
属性图: 相较于异构图, 属性图给图数据增加了额外的属性信息, 如下图所示。对于一个属性图而言, 节点和关系都有标签(Label)和属性 (Property),这里的标签是指节点或关系的类型, 如某节点的类型为 “用户”,属性是节点或关系的附加描述信息, 如 “用户” 节点可 以有“姓名” “注册时间” “注册地址”等属性。属性图是一种最常见的工业级图数据的表示方式, 能够广泛适用于多种业务场景下的数据表达。
非显式图: 非显式图是指数据之间没有显式地定义出关系, 需要依据某种规则或计算方式将数据的关系表达出来, 进而将数据当成一种图数据进行研 究。比如计算机3D视觉中的点云数据, 如果我们将节点之间的空间距离转化成关系的话, 点云数据就成了图数据。 其他: 动态图: 图中的节点或者边都是随着时间变化的, 可能增加或减少, 一般是图的构成是按照时间片来构成, 每一个时间片一个图的表示, 例 如 \(\mathrm{t} 1\) 时刻的图是初始图, \(\mathrm{t} 2\) 时刻的图就是节点或连边变化后的图一直到 \(\operatorname{tn}\) 时刻
1.13 图嵌入
网络嵌入,即网络表示学习(NRL),旨在将网络嵌入到一个低维空间中,同时保持网络的结构和性质,以便将学习到的嵌入应用于下游网络任务。例如,基于随机游走的方法、基于深层神经网络的方法、基于矩阵分解的方法以及其他方法,例如LINE。然而,所有这些算法都是针对同构图提出的。
异构图嵌入主要关注基于元路径的结构信息的保存。ESim接受用户定义的元路径作为指导,在用户首选的嵌入空间中学习顶点向量,以进行相似性搜索。即使ESim可以利用多个元路径,它也无法了解元路径的重要性。为了获得最佳性能,ESim需要进行网格搜索以找到hmeta路径的最佳权重。很难找到特定任务的最佳组合。Metapath2vec设计了一种基于元路径的随机游走,并利用skip-gram执行异构图嵌入。然而,metapath2vec只能使用一条元路径,可能会忽略一些有用的信息。与metapath2vec类似,HERec提出了一种类型约束策略来过滤节点序列并捕获异构图中反映的复杂语义。HIN2Vec执行多个预测训练任务,同时学习节点和元路径的潜在向量。Chen等人提出了一种投影度量嵌入模型,称为PME,该模型可以通过欧几里得距离保持节点的近邻。PME将不同类型的节点投影到同一关系空间,并进行异构链路预测。为了研究异构图的综合描述问题,Chen等人提出了通过边表示嵌入异构图的HEER。Fan等人提出了一种嵌入模型metagraph2vec,其中最大限度地保留了恶意软件检测的结构和语义。Sun等人提出了基于元图的网络嵌入模型,该模型同时考虑了元图中所有元信息的隐藏关系。总之,上述所有算法都没有考虑异构图表示学习中的注意力机制。
1.14 元路径
元路径 meta-path 元路径是属于异构图的一个概念。在异构图中,两个节点可以通过不同的路径产生关联。在电商场景的异构图中,可以通过“买家-商家-买家”和“买家-设备-买家”连接两个不同的买家,而不同的路径则具有语义上的不同,元路径meta-path即用来表示连接两个实体的一条特定的路径。
1.15 动态图、静态图
静态图指的是图的节点和边都是固定的,不会随时间变化
而实际上在现实世界中,图的节点和边往往都是动态变化的,边会动态增加(用户购买新的商品、用户关注另一个用户),节点会增加(新网页上线、新用户注册),节点的属性会变化(用户的属性会随时间变化)等。基于静态图去解决问题,虽然处理起来更简单,但不符合实际,预测效果也会大打折扣。边都是会动态变化的,会出现节点和边的动态增加、动态减少以及属性的动态变化。虽然动态图更符合实际,但因为要研究的目标是在图上动态变化的,可以想象研究难度会比静态图高不少
1.16 经典图嵌入方法
1.17 deepwalk-2014
首先打乱节点顺序,以每个节点为起点,通过随机游走到方式生成节点序列,使用skip-gram算法来学习Embedding。
随机游走过程比较简单,在遍历每个节点到时候随机选择一个邻居节点作为序列的下一个节点,一直到需要到最大长度停下来。对于有向图和带有权重到图,可以根据实际情况来调整选择邻居节点的概率。刘下
DeepWalk是一种基于随机游走的方法生成顶点嵌入的方法,用于同构图。可以分为三步:
第一步:采样。以每个结点为起点随机游走的方式获得一个序列。论文作者认为每个结点进行32~64次游走,每次游走的长度为40.
第二步:训练Skip-gram模型。每一个结点对应一个embedding向量,然后使用基于分层Softmax框架的Skip-gram模型训练。通常窗口大小为21,即左右各10个。
第三步:获取embedding映射表。
DeepWalk的随机游走方式是完全随机的,有没有更好的策略呢? Node2vec
1.18 node2vec-2016
相比于DeepWalk采用了不同的随机游走策略,形成序列,类似skip-gram方式生成节点embedding
node2vec是为了学习到节点的同质性和结构相似性,那就先说下这两个 同质性:节点跟周围节点Embedding相似 结构相似性:图中相同结构的节点Embedding相似 类似于广度优先遍历(BFS)和深度优先遍历(DFS)的方式生成节点序列,拿到的序列通过skip-gram,分别学习节点的结构性和同质性,另外通过超参权衡两种特性得到最终的学习结果。
算法通过控制参数p和q可以来控制bfs和dfs模式,当p较小是,倾向于游走在t节点附近生成序列,当q较小是倾向于游走到相对于t节点更远的地方生成序列。刘下
1.19 SDNE
使用自编码器进行学习的方式捕获一阶二阶的相似性
1.20 LINE
捕获节点的一阶和二阶相似度,分别求解,再将一阶二阶拼接在一起,作为节点的embedding.
LINE的优化目标是一阶相似度和二阶相似度刘下 1、一阶相似度指两个直接相连节点的相似度,当没有边相连,相似度为0;当相连且权重很大时相似度很高。 2、二阶相似度指邻居节点的相似度,即拥有相同邻居的节点被认为是相似的,如果有很多共有邻居节点且权重较大,则相似度很高。
基于一阶相似度如何优化? 首先定义了两个向量的联合概率分布为两个向量内积经过sigmoid的输出值(两个低维Embedding向量经过sigmoid规约到0-1之间的值) 两个向量的经验分布可使用连接两个节点之间的edge的权重在全图中的权重占比 如此,通过KL-divergence来计算两个分布之间差异,通过最小化KL-divergence即可达到优化embedding的效果,即(2),通过对KL公式进行简化,即可得到式(3)
公式2 \[ O_1=d\left(\hat{p}_1(\cdot, \cdot), p_1(\cdot, \cdot)\right), \] 公式3
\[ O_1=-\sum_{(i, j) \in E} w_{i j} \log p_1\left(v_i, v_j\right) \]
简单理解下,倘若graph中有两个节点,那么经验分布应该为1,联合概率分布优化后也应该为1,即两个向量内积应该趋于正无穷。另外一点,值得注意的是一阶相似性只用在无向图中。
基于二阶相似度如何优化 相较于一阶相似度,仍然使用KL-divergence分布之间的差异来优化embedding,是不过embedding的联合概率分布和经验分布的定义和计算方法有所改变 联合概率为两个相连的向量相对于与其连接所有向量的占比,使用sofamax计算如式(4) 经验分布为连接两个节点edge的权重在与其为出变的总权重占比
其他同一阶相似度,使用kl-divergence计算差异即(5),通过约简后如式(6)
二阶相似度可用于计算有向图,另外如何融合一二阶向量的方法直接concat到一起,当然也可以使用其他方法。
公式4
\[ p_2\left(v_j \mid v_i\right)=\frac{\exp \left(\vec{u}_j^{\prime T} \cdot \vec{u}_i\right)}{\sum_{k=1}^{|V|} \exp \left(\vec{u}_k^{\prime T} \cdot \vec{u}_i\right)}, \]
公式5 \[ O_2=\sum_{i \in V} \lambda_i d\left(\hat{p}_2\left(\cdot \mid v_i\right), p_2\left(\cdot \mid v_i\right)\right) \]
公式6
\[ O_2=-\sum_{(i, j) \in E} w_{i j} \log p_2\left(v_j \mid v_i\right) \]
1.21 pagerank
1.22 struc2vec
对图的结构信息进行捕获,在其结构重要性大于邻居重要性时,有较好的效果
1.23 同构图-图神经网络算法
1.24 GCN
图神经网络算法的开山之作~
image卷积的本质:将图像的局部信息进行提取,或者说对图像中的一个区域进行汇总。
graph卷积的本质:将结点的邻居(包括自己)的信息进行汇总,然后更新隐向量的过程。黎明程序员
1.24.1 图结构
GCN也可以像CNN一样叠加多层,整体网络结构如下图所示:

1.24.2 GCN隐藏层传播
\(H^{(l+1)}=\sigma\left(\tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}} H^{(l)} W^{(l)}\right)\)
其中,:(1) \(\tilde{A}=A+I_N\) ,这里指无向图的邻接矩阵,但是添加了自连接(下图中的红线),也 就是每个节点也可以指向自己, \(I_N\) 代表第 \(\mathrm{N}\) 个节点矩阵实体,另外 \(\tilde{D}=\sum_j \tilde{A_{i j}}=D+I\) 这 里相当于节点的度加1形成的矩阵 (用这个度矩阵进行归一化), \(W^{(l)}\) 是一个可训练的参数矩 阵,(2) \(\sigma(\cdot)\) 代表激活函数,比如 \(R E L U(\cdot)=\max (0, \cdot)\) ;(3) \(H^l \in R^{N \times D}\) 代表 \(l^{\text {th }}\) 层的隐 向量矩阵, \(H^0=X\) ;
\(A\) 波浪 \(=A+1\) ,1是单位矩阵,相当于是无向图G的邻接矩阵加上自连接(就是每个顶点和自身加一条边) 如此一来消息聚合时不仅能聚合来自其他结点的消息,还能聚合结点自身的消息。99.99%
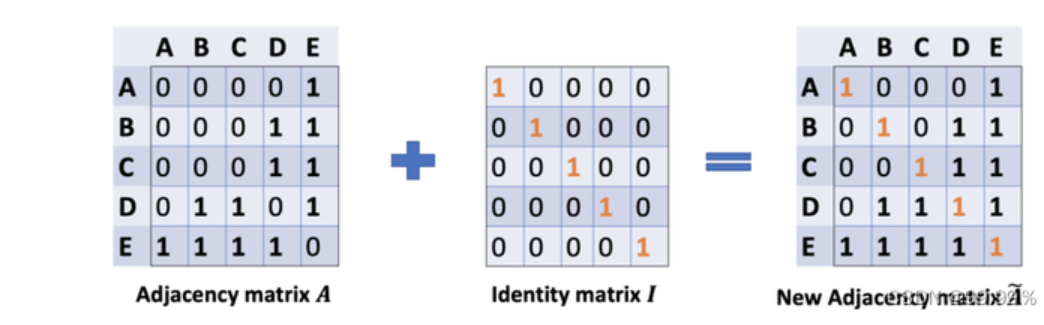
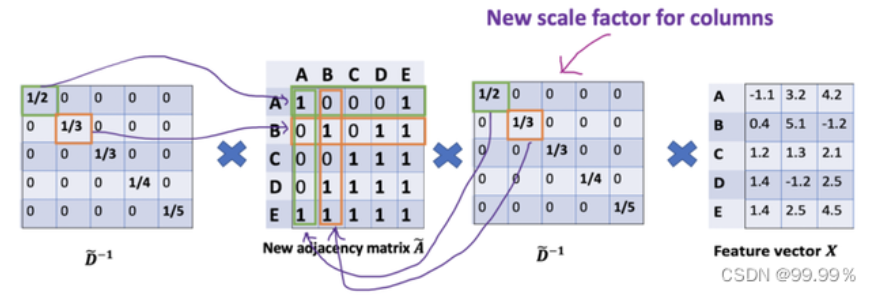
D波浪是A波浪的度矩阵 (degree matrix),公式为 \(\mathrm{D}\) 波浪 \(\mathrm{ii}=\sum \mathrm{jA}\) 波浪(无向图里,节点的度就是节点连接的边的个数。) \(\mathrm{H}\) 是每一层的特征,对于输入层的话, \(\mathrm{H}\) 就是X (初始就给定的) \(\sigma\) 是像Softmax、ReLU这样的非线性激活函数 \(\mathrm{W}\) 就是每一层模型的参数,也就是模型给节点特征乘上的权重,这是模型需要训练的参数,即权值矩阵 他们之间的运算,就是各矩阵相乘,部分内容就长这样:
1.24.3 损失函数
GCN 是一个多层的图卷积神经网络,每一个卷积层仅处理一阶邻域信息,通过叠加若干卷积层可以实现多阶邻域的信息传递。 从输入层开始,前向传播经过图卷积层运算,然后经过softmax激活函数的运算得到预测分类概率分布。 softmax的作用是将卷积网络的输出的结果进行概率化,我直接将Softmax理解为依据公式运算出样本点的类别。 假设我们构造一个两层的 GCN,激活函数分别采用ReLU和Softmax,则整体的正向传播的公式为:
\[ Z=f(X, A)=\operatorname{softmax}\left(\hat{A} \operatorname{ReLU}\left(\hat{A} X W^{(0)}\right) W^{(1)}\right) \]
该模型实际是输入层+隐藏层(图卷积层,类似全连接层的作用)+SoftMax+输出层构成的,GCN模型可视化为:

GCN输入一个图,通过若干层GCN每个node的特征从X变成了Z,但是,无论中间有多少层,node之间的连接关系,即邻接矩阵A,都是共享的。
倒入数据
import math
import time
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import scipy.sparse as sp
import argparse
def encode_onehot(labels):
"""使用one-hot对标签进行编码"""
classes = set(labels)
classes_dict = {c: np.identity(len(classes))[i, :] for i, c in
enumerate(classes)}
labels_onehot = np.array(list(map(classes_dict.get, labels)),
dtype=np.int32)
return labels_onehot
def normalize(mx):
"""行归一化"""
rowsum = np.array(mx.sum(1))
r_inv = np.power(rowsum, -1).flatten()
r_inv[np.isinf(r_inv)] = 0.
r_mat_inv = sp.diags(r_inv)
mx = r_mat_inv.dot(mx)
return mx
def sparse_mx_to_torch_sparse_tensor(sparse_mx):
"""将一个scipy sparse matrix转化为torch sparse tensor."""
sparse_mx = sparse_mx.tocoo().astype(np.float32)
indices = torch.from_numpy(
np.vstack((sparse_mx.row, sparse_mx.col)).astype(np.int64))
values = torch.from_numpy(sparse_mx.data)
shape = torch.Size(sparse_mx.shape)
return torch.sparse.FloatTensor(indices, values, shape)
def load_data(path="./cora/", dataset="cora"):
"""读取引文网络数据cora"""
print('Loading {} dataset...'.format(dataset))
idx_features_labels = np.genfromtxt("{}{}.content".format(path, dataset),
dtype=np.dtype(str)) # 使用numpy读取.txt文件
features = sp.csr_matrix(idx_features_labels[:, 1:-1], dtype=np.float32) # 获取特征矩阵
labels = encode_onehot(idx_features_labels[:, -1]) # 获取标签
# build graph
idx = np.array(idx_features_labels[:, 0], dtype=np.int32)
idx_map = {j: i for i, j in enumerate(idx)}
edges_unordered = np.genfromtxt("{}{}.cites".format(path, dataset),
dtype=np.int32)
edges = np.array(list(map(idx_map.get, edges_unordered.flatten())),
dtype=np.int32).reshape(edges_unordered.shape)
adj = sp.coo_matrix((np.ones(edges.shape[0]), (edges[:, 0], edges[:, 1])),
shape=(labels.shape[0], labels.shape[0]),
dtype=np.float32)
# build symmetric adjacency matrix
adj = adj + adj.T.multiply(adj.T > adj) - adj.multiply(adj.T > adj)
features = normalize(features)
adj = normalize(adj + sp.eye(adj.shape[0]))
idx_train = range(140)
idx_val = range(200, 500)
idx_test = range(500, 1500)
features = torch.FloatTensor(np.array(features.todense()))
labels = torch.LongTensor(np.where(labels)[1])
adj = sparse_mx_to_torch_sparse_tensor(adj)
idx_train = torch.LongTensor(idx_train)
idx_val = torch.LongTensor(idx_val)
idx_test = torch.LongTensor(idx_test)
return adj, features, labels, idx_train, idx_val, idx_test
GCN框架
class GCNLayer(nn.Module):
"""GCN层"""
def __init__(self,input_features,output_features,bias=False):
super(GCNLayer,self).__init__()
self.input_features = input_features
self.output_features = output_features
self.weights = nn.Parameter(torch.FloatTensor(input_features,output_features))
if bias:
self.bias = nn.Parameter(torch.FloatTensor(output_features))
else:
self.register_parameter('bias',None)
self.reset_parameters()
def reset_parameters(self):
"""初始化参数"""
std = 1./math.sqrt(self.weights.size(1))
self.weights.data.uniform_(-std,std)
if self.bias is not None:
self.bias.data.uniform_(-std,std)
def forward(self,adj,x):
support = torch.mm(x,self.weights)
output = torch.spmm(adj,support)
if self.bias is not None:
return output+self.bias
return output
class GCN(nn.Module):
"""两层GCN模型"""
def __init__(self,input_size,hidden_size,num_class,dropout,bias=False):
super(GCN,self).__init__()
self.input_size=input_size
self.hidden_size=hidden_size
self.num_class = num_class
self.gcn1 = GCNLayer(input_size,hidden_size,bias=bias)
self.gcn2 = GCNLayer(hidden_size,num_class,bias=bias)
self.dropout = dropout
def forward(self,adj,x):
x = F.relu(self.gcn1(adj,x))
x = F.dropout(x,self.dropout,training=self.training)
x = self.gcn2(adj,x)
return F.log_softmax(x,dim=1)模型评估
def accuracy(output, labels):
preds = output.max(1)[1].type_as(labels)
correct = preds.eq(labels).double()
correct = correct.sum()
return correct / len(labels)
def train_gcn(epoch):
t = time.time()
model.train()
optimizer.zero_grad()
output = model(adj,features)
loss = F.nll_loss(output[idx_train],labels[idx_train])
acc = accuracy(output[idx_train],labels[idx_train])
loss.backward()
optimizer.step()
loss_val = F.nll_loss(output[idx_val],labels[idx_val])
acc_val = accuracy(output[idx_val], labels[idx_val])
print('Epoch: {:04d}'.format(epoch+1),
'loss_train: {:.4f}'.format(loss.item()),
'acc_train: {:.4f}'.format(acc.item()),
'loss_val: {:.4f}'.format(loss_val.item()),
'acc_val: {:.4f}'.format(acc_val.item()),
'time: {:.4f}s'.format(time.time() - t))
def test():
model.eval()
output = model(adj,features)
loss_test = F.nll_loss(output[idx_test], labels[idx_test])
acc_test = accuracy(output[idx_test], labels[idx_test])
print("Test set results:",
"loss= {:.4f}".format(loss_test.item()),
"accuracy= {:.4f}".format(acc_test.item()))
if __name__ == '__main__':
# 训练预设
parser = argparse.ArgumentParser()
parser.add_argument('--no-cuda', action='store_true', default=False,
help='Disables CUDA training.')
parser.add_argument('--fastmode', action='store_true', default=False,
help='Validate during training pass.')
parser.add_argument('--seed', type=int, default=42, help='Random seed.')
parser.add_argument('--epochs', type=int, default=200,
help='Number of epochs to train.')
parser.add_argument('--lr', type=float, default=0.01,
help='Initial learning rate.')
parser.add_argument('--weight_decay', type=float, default=5e-4,
help='Weight decay (L2 loss on parameters).')
parser.add_argument('--hidden', type=int, default=16,
help='Number of hidden units.')
parser.add_argument('--dropout', type=float, default=0.5,
help='Dropout rate (1 - keep probability).')
args = parser.parse_args()
np.random.seed(args.seed)
adj, features, labels, idx_train, idx_val, idx_test = load_data()
model = GCN(features.shape[1],args.hidden,labels.max().item() + 1,dropout=args.dropout)
optimizer = optim.Adam(model.parameters(),lr=args.lr,weight_decay=args.weight_decay)
for epoch in range(args.epochs):
train_gcn(epoch)1.25 graphSAGE
严格来说graphsage并不是一种新的图算法,而是一种推导式图学习方法。训练时Graphsage 分为两步:邻居采样和特征聚合。这与普通图算法没有差异,只是训练时对每一个节点构建相应的子图,然后所有子图相同层的权重矩阵共享。邻居聚合时可以选用不同聚合方式,比如图卷积(GCN), 图注意力机制(GAT) 以及最大池化(max pooling) 等,这相当于集大成者。
相比 GCN 和 GAT,预测时graphsage不需要把新节点加入图中更新全图重新训练,而是根据新节点构建子图,然后利用训练得到的各层参数直接计算预测。
取代原来为每个节点独立训练embedding的方法(原来的transductive 直推式的框架只能对固定的图生成embedding
,transductive 方法在处理以前从未见过的数据时效果不佳),GraphSAGE采用采样和聚合的方法,是一个inductive(归纳式的框架,归纳式能够处理图中新增的节点,或者通过之前学习的图的知识,用于新图label 的推断上),能够同时利用节点特征信息和结构信息得到Graph Embedding的映射,并且能够高效地利用节点的属性信息对新节点生成embedding。可以同时学习每个节点邻域的拓扑结构以及节点特征在邻域中的分布。 相比之前的方法,之前都是保存了映射后的结果(一次性的,只能学习已经存在的图,不记录转换的过程),而GraphSAGE保存了生成embedding的映射(学习了一个计算函数,泛化能力强),可扩展性更强,对于节点分类和链接预测问题的表现也比较好(动态图)。Brauch
总结:
提出归纳式(节点的局部信息和图的全局信息)的graph embedding方法,之前的graph embedding方法都是所有节点都在图中,对于没有看到过的节点是不能处理的,这种叫做直推式方法。
而GraphSAGE这种归纳式的方法,可以对于没见过的节点也生成embedding。
GraphSAGE不仅限于构建embedding,也通过聚合周围邻居节点的特征。
1、通过聚合邻居节点或者全局信息,concat聚合信息和上一层度信息得到每一层的信息 2、邻居节点采样,如果需要大于有的,直接采样,否则在邻居中重复采样 3、对于聚合函数,目的是将周围邻居节点聚合成一个向量,由于图本身是没有顺序的,所以要求顺序或排列不变性,如mean、max,对于lstm,本身是有顺序的,通过输入节点的随机化能够使lstm适用于无序集合
与GCN的不同之处: GCN需要图中的每个节点,如A和D矩阵,而GraphSAGE只需要知道邻居节点
1.26 GAT
真实图中往往包含大量噪声,邻居的相对重要性有差异。GAT 在邻居聚合时给不同邻居赋不同权 重即 “注意力系数” (attention coefficient),这样在邻居做完加权求和后吸收重要邻居特征,减 少了噪声影响。 注意力系数通过计算邻居节点与目标节点相似度然后通过softmax 归一化得到,如式4 \[ \begin{gathered} \alpha_{i j}=\operatorname{softmax}_j\left(e_{i j}\right)=\frac{\exp \left(e_{i j}\right)}{\sum_{k \in \mathcal{N}_i} \exp \left(e_{i k}\right)} . \\ \text { 式 (4) } \end{gathered} \] 目标节点特征是通过邻居特征与各自注意力系数相乘然后加权求和获得。为捕获更多信息,GAT 中还可以使用多头 attention,如下图10为论文中采用3个 attention头的特征聚合方式。
1.27 异构图
1.28 RGCN
一个类别给弄一个矩阵算embedding,一个关系对一整张图共用一个矩阵。 结构如下

\[ h_i^{(l+1)}=\sigma\left(\sum_{r \in \mathcal{R}} \sum_{j \in \mathcal{N}_i^r} \frac{1}{c_{i, r}} W_r^{(l)} h_j^{(l)}+W_0^{(l)} h_i^{(l)}\right) \] ,R为关系结合,N为邻居点集合,c为一个常量(正则化系数),RGCN的参数都在模型参数 中,它没有用度矩阵D及邻接矩阵A作为边的权重的,而是在模型中参数自学,一步步看这个式子,上式是在 \(h_i\) 这个向量上做的信息聚合,为第 \(l\) 层,以 \(h_i^l\) 表示。这样一个向 量首先用一个矩阵 \(W_0^l\) 来将其自身做embedding后,加上本层网络中所有邻居节点所表示的向量 \(h_j^l\) 乘上其相应参数矩阵 \(W_r^l\) 之和(这里的 \(r\) 由 \(j\) 节点与 \(i\) 节点连接的关系决定),最后通过一 个激活函数 \(\sigma\) 来获得下一层的embedding。这里的 \(c\) 是一个正则化参数。 这样硬train一发真的管用吗?还真管用了,但很遗憾没有完全管用。 问题的来源正是参数矩阵 \(W\) ,这个稠密矩阵事实上完全由节点向量长度与特征个数决定,一旦 relation过多,文中指出模型就会出现过拟合稀缺边的情况。即一旦某类边变的稀有,他们很容易 在决定最终label时起到关键作用。作者给出了两张解决方案,这两者也很直接,都是直接拿 \(W\) 开刀: - basis decomposition:这一方案退回了原来GCN的方式,但将各个relation之间的weights共 享,而对于每一个关系只有唯一的一个参数 \(a_{r b}\) ,写作 \(W_r^{(l)}=\sum_{b=1}^B a_{r b}^{(l)} V_b^{(l)}\) - block-diagonal-decomposition: 上一种方案显得将模型的灵活度收缩的过窄,那么有无折中 的办法呢? 这里作者将 \(W\) 矩阵分块对角化, \(Q_{b r}\) 即是分块矩阵,其数目为一个超参数,由人设 定。这使得参数减少的同时获得了一定的可变性,写作 \(W_r^{(l)}=\bigoplus_{b=1}^B Q_{b r}^{(l)}\) 本文使用的损失函数也是常规的交叉熵函数,先看下一篇,最后再总结。知乎
提出了一个异构图中多关系融合的一个方式(就是不同关系分别做融合,然后叠加处理,得到node表示) 降低多关系引起的参数剧增,提出了因子分解以及多关系参数共享的方式。 对比一下GCN,GCN是采用度矩阵D及邻接矩阵A作为一个加权求和的特征融合,RGCN并没有用度矩阵D及邻接矩阵A作为边的权重的,而是把这部分都放在模型中参数自学。
RGCN是作为一个异构图的关系融合的一个简单方法,提供了一个多关系处理的方法。现在来看,RGCN肯定是不够看了,起码能想到优化的点就是,你都把权重都放参数里了,那你得有个attention是不是更好呢? 说到这,那HAN就来了,下回就看看HAN。
1.29 ESim
一种异构图嵌入方法,可以从多个元路径中捕获语义信息
1.30 HAN
HAN是首次尝试研究基于注意力机制的异构图神经网络。将流行的多头自注意力机制用于异构图的元路径节点特征表示,然后通过语义级注意力加权汇总元路径注意力得到最终节点语义表示,其包含了节点特征和邻域结构特征。zhihu 基于层次注意力的异构图神经网络,包括节点级注意力和语义级注意力。具体而言,节点级注意力旨在了解节点与其基于元路径的邻居之间的重要性,而语义级注意力能够了解不同元路径的重要性。通过学习节点级和语义级注意力的重要性,可以充分考虑节点和元路径的重要性。然后,该模型可以通过分层聚合基于元路径的邻居的特征来生成节点嵌入。
1.31 GTN
1.32 meatpath2vec
一种异构图嵌入方法,该方法执行基于元路径的随机行走,并利用skip-gram图嵌入异构图
1.33 GATNE
1.34 BiNE
1.35 SGCN
1.36 SiGAT
1.37 SDGNN
1.38 动态图
参考:https://zhuanlan.zhihu.com/p/490456974
动态网络模型在静态网络的基础上增加了时间维度,使其能同时表征复杂系统的结构和时序信息,在生物、医药、社交网络等领域被广泛使用 动态(Dynamic)网络与静态(Static)网络的区别在于前者具有:1)动态结构,连边和节点会随时间消失/出现,2)动态属性,节点和连边状态会随时间而改变高飞
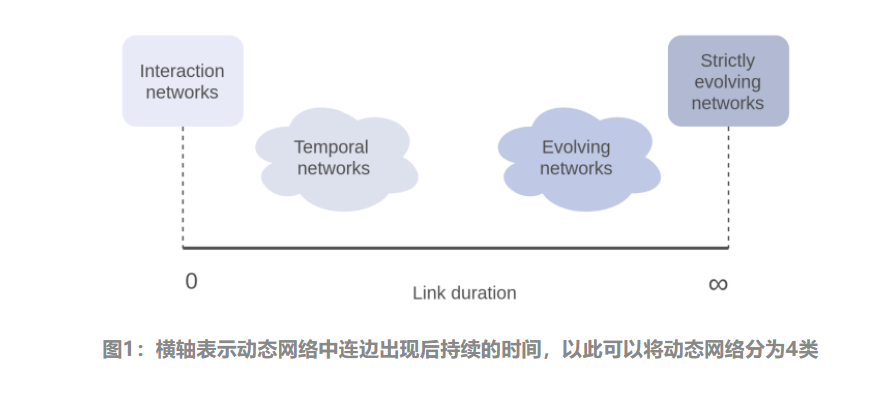
网络的结构的动态变化体现为网络连边和节点的出现和消失,这种变化的不同决定了动态网络的性质。例如,Email网络中的新连边(互发邮件)瞬时出现和消失,而文献引用网络中的连边(相互引用)出现后便永不会消失。根据这种变化的持续时间对动态网络进行分类,可以区分动态网络的演化机理。
首先考虑连边出现到消失的时间(持续时间),按照连边持续时间长短,可以在时间轴上将动态网络分为如图4类:
1.39 CTDNE
CTDNE是在DeepWalk基础上发展出来的算法框架,也是训练图中节点的embedding表示。在图1中,每条边可以代表现实生活中两个实体(如用户、商品等)的一次交互(如打电话、发邮件、关注等),边上的数字代表交互发生的时间。 CTDNE认为,一条合理的时序路径(temporal walk)应该满足规则:“路径中每条边的时间都应该小于等于下一条边的时间”。在满足这一规则的基础上,还需要确定两个随机采样方式。初始节点/边的采样方式以及采样下一个满足规则的邻居节点/边的采样方式。论文通过实验证明,对于初始边的采样使用线性增长的采样最好,也就是一条边的被采样概率随着边的发生时间增长而线性增长。而对于采样下一条边,在满足下一条边的时间大于等于当前边的条件下,采样等概率采样的方式更好。 总结起来,CTDNE就是在DeepWalk基础上,通过修改路径采样方式使得路径满足实际的发生顺序,从而使得采样路径更加合理。paddlepaddle
1.40 DySAT
1.41 EvolveGCN
在时间维度上采用了图卷积网络(GCN)模型而没有借助节点嵌入。该方法通过使用RNN演化GCN参数,以捕获图序列的动态
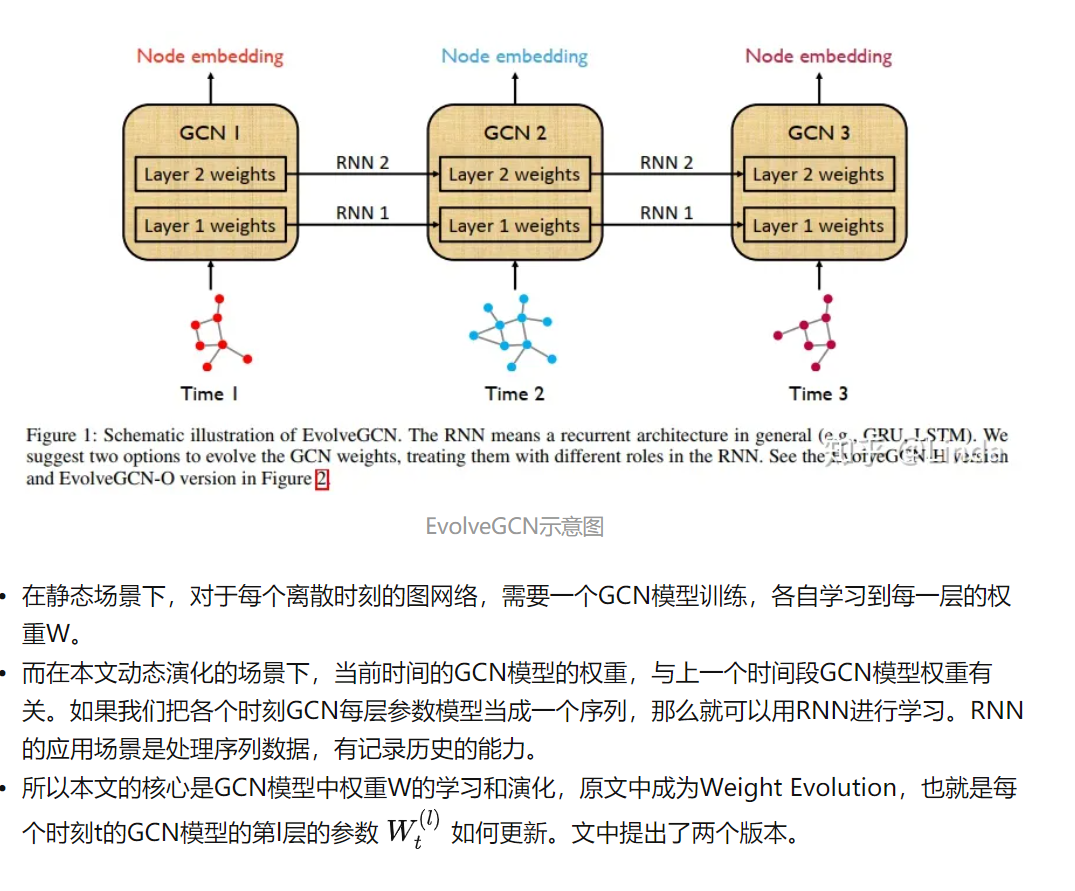
1.41.1 Evolve-O
1.41.2 Evolve-H
1.42 DGNN
1.43 TGAT
1.44 HGNN
1.45 DHGNN
1.46 二部图
定义 设无向图 \(G=<V, E>\), 若能将 \(V\) 划分成 \(V_1\) 和 \(V_2\) \(\left(V_1 \cup V_2=V, V_1 \cap V_2=\varnothing\right)\), 使得 \(G\) 中的每条边的两个端 点都一个属于 \(V_1\), 另一个属于 \(V_2\), 则称 \(G\) 为二部图, 记为 \(<V_1, V_2, E>\), 称 \(V_1\) 和 \(V_2\) 为互补顶点子集. 又若 \(G\) 是简单图, 且 \(V_1\) 中每个顶点都与 \(V_2\) 中每个 顶点相邻, 则称 \(G\) 为完全二部图, 记为 \(K_{r, s}\), 其中 \(r=\left|V_1\right|\), \(s=\left|V_2\right|\).